Purpose of Version Control
Multiple people can work simultaneously on a single project. Everyone works on and edits their own copy of the files and it is up to them when they wish to share the changes made by them with the rest of the team. Enables one person to use multiple computers to work on a project. It integrates the work that is done simultaneously by different members of the team. Version control provides access to the historical versions of a project. This is insurance against computer crashes or data loss. If any mistake is made, we can easily roll back to a previous version. It is also possible to undo specific edits that too without losing the work done in the meanwhile. It can be easily known when, why, and by whom any part of a file was edited.
Benefits of the Version Control System
Managing and protecting the source code. Complete the long-term change history of every file. It keeps every change made by many individuals over the years. Enhances the project development speed by providing efficient collaboration. Comparing earlier versions of the code Leverages the productivity, expedites product delivery, and skills of the employees through better communication and assistance, Reduce possibilities of errors and conflicts meanwhile project development through traceability to every small change. Team members or contributors of the project can contribute from anywhere irrespective of the different geographical locations through VCS. For each different contributor to the project, a different working copy is maintained and not merged to the main file unless the working copy is validated. Helps in recovery in case of any disaster or contingent situation. Informs about Who, What, When, and Why changes have been made.
There are two types of version control systems: centralized and distributed.
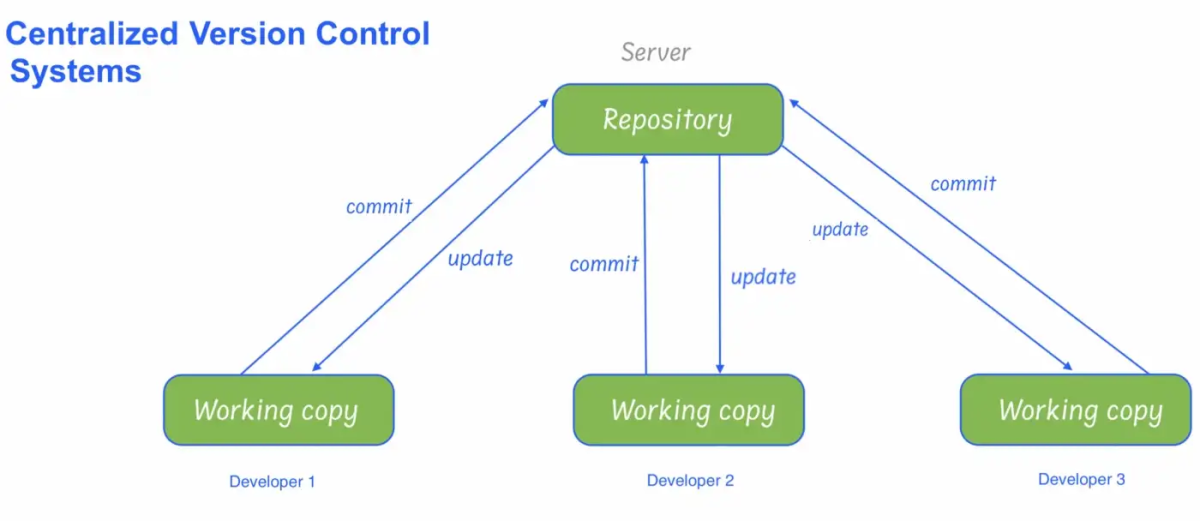
1. Centralized Version Control Systems
In a centralized version control system (CVCS), a server acts as the main repository that stores every version of code. Centralized version control systems are based on the idea that there is a single “central” copy of your project somewhere (probably on a server), and a team member will “commit” their changes to this central copy. Using centralized source control, every user commits directly to the main branch, so this type of version control often works well for small teams, because team members have the ability to communicate quickly so that no two developers want to work on the same piece of code simultaneously.Centralized source control systems, such as CVS, Perforce, and SVN, require users to pull the latest version from the server to download a local copy on their machine. Contributors then push commits to the server and resolve any merge conflicts on the main repository.
Advantages
Works well with binary files Offers full visibility Grant access level control on the directory level Relatively easy to set up Provides transparency More control over users and their access.
Disadvantages
If the main server goes down, developers can’t save versioned changes. It is not locally available, which means we must connect to the network to perform operations. Remote commits are slow. For every command, CVCS connects the central server which impacts the speed of operation. During the operations, if the central server gets crashed, there is a high chance of losing the data.
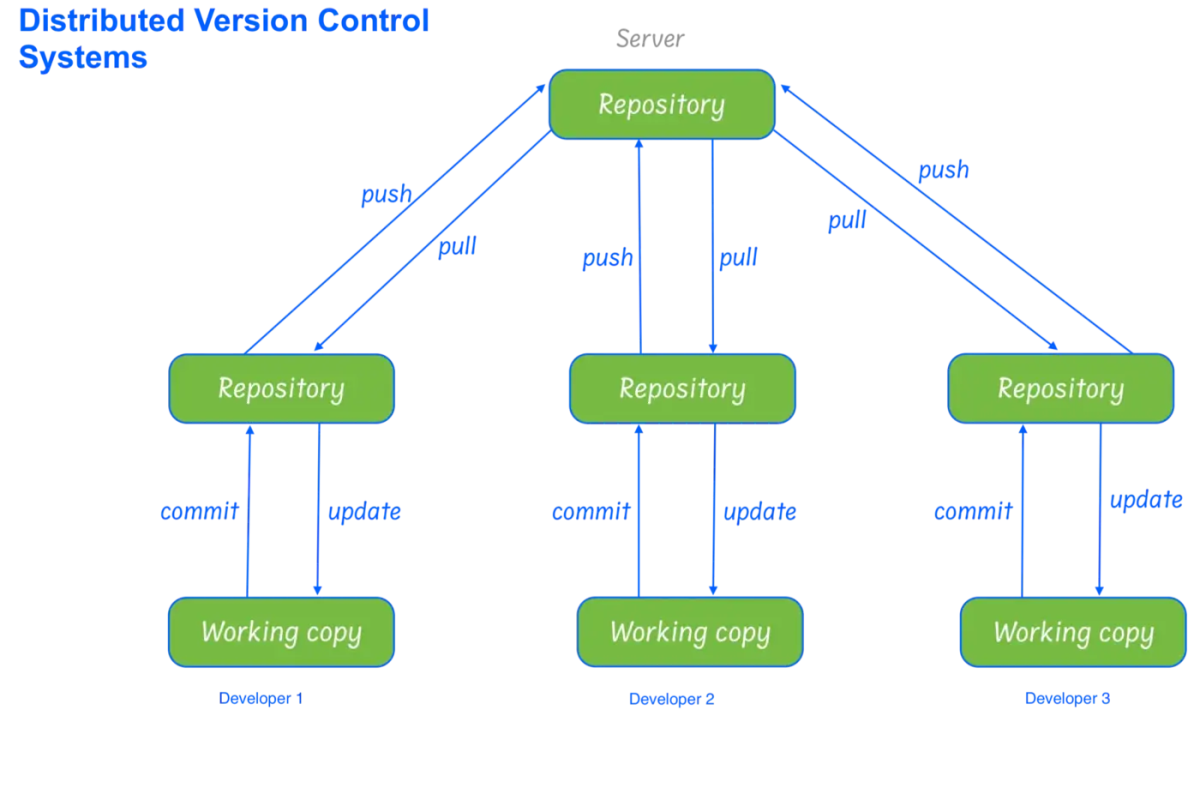
2. Distributed Version Control Systems
In distributed version control, most of the mechanism or model applies the same as centralized. The only major difference here is instead of one single repository, which is the server, every single developer or client has their own server and they will have a copy of the entire history or version of the code and all of its branches in their local server or machine. This means that everyone has a working copy of the repository that keeps track of his changes and the different releases made by him or by his colleagues.Git and Mercurial are the most used distributed systems in software engineering.
Advantages
Except for pushing and pulling the code, the user can work offline in DVCS, due to this the full history is always available. DVCS is faster than CVCS because you don’t need to communicate with the remote server for each and every command. Merging and branching the changes in DVCS is very easy. No need to access a remote server therefore the performance of DVCS is better. If the main server goes down or it crashes in DVCS, you can still get the backup or entire history of the code from your local repository or server where the full revision of the code is already saved. Because of local commits, the full history is always available. Ability to push your changes continuously Good for projects with off-shore developers
Disadvantages
Working with a lot of binary files requires a huge amount of space, and developers can’t do diffs. Projects with a long history, i.e., a large number of change sets may take a lot of time and occupy more disk space. It may not always be obvious who did the most recent change File locking doesn’t allow different developers to work on the same piece of code simultaneously. It helps to avoid merge conflicts but slows down development. DVCS enables you to clone the repository—this could mean a security issue Managing non-mergeable files is contrary to the DVCS concept
DVCS vs. CVCS
DVCS focuses on sharing changes; every change has a guid or unique id. Every developer has one local copy of the source code repository, in addition to the central source code repository. Distributed systems have no forced structure. You can create “centrally administered” locations or keep everyone as peers. DVCS enables working offline. Apart from push and pull actions, everything is done locally.
CVCS focuses on synchronizing, tracking, and backing up files. CVCS works based on a client-server relationship, with the source repository located on one single server, providing access to developers across the globe. Recording/downloading and applying a change are separate steps in a centralized system, they happen together. CVCS relies on internet connectivity for access to the server.
Popular Key Terms
Repository: It can be described as the heart of any version control system. It is the central defined place where all the developers or programmers work and store their code. Apart from storing files, repositories also maintain the history. In version control systems, repositories are accessed over a network which acts like a server and version control tool as a client. On establishing successful connections, clients store or retrieve their changes. Trunk: A trunk can be defined as a directory where all the development takes place. All the check-outs are committed by the developers. Tags: Tags help create snapshots of the project. The operation of creating tags allows keeping descriptive and memorable names to a specific version in the repository. Branches: Branches of the repository are like branches of the tree. The operation of creating branches is used to create another line of development. It is proved beneficial when your development process forks in two directions. Working copy: It is the snapshot of the repository where the developer is actively working on it. Each developer has their own working copy. The changes made in the working copy are merged together in the main repository. A working copy can be considered as a private workplace where developers maintain their work in a systematic way which is isolated from the rest of the developers. Commit changes: Committing code is the process of storing changes from a working copy to the central server. After successful commit changes are made available to all the team members. Other developers can pull these changes which will update the working copy. Commit is an atomic operation which means either it is successful or rolled back. Developers can never see a half-finished commit. Revision: A numbered draft of specific updates to individual files. Each time you edit a file and commit it back to the repository, the file’s revision number increases. Version: The numbering scheme is used to identify sets of files that are tagged and named at a certain point in time. Conflict: When two developers make changes to their working copies of the same file and commit them to the repository, their work may conflict. When this happens, CVS will detect the conflict and require someone to resolve it before committing their changes. Merging: Combining multiple changes made to different working copies of the same files in the source repository. Merging is a strategy for managing conflicts by letting multiple developers work at the same time (with no locks on files), and then incorporating their work into one combined version. Merging works well when two sets of changes are made to different lines in files and can be easily combined. When changes to a file are made on the same line or lines, conflicts occur, requiring someone to edit the file manually before the changes can be committed to the source repository successfully. Resolving: Conflicts within a file created by two developers attempting to commit conflicting changes must be addressed by manually editing the file. Someone must go through the file line by line to accept one set of changes and delete the other set. Files with conflicts cannot be committed into the source repository successfully until they are resolved. This article is accurate and true to the best of the author’s knowledge. Content is for informational or entertainment purposes only and does not substitute for personal counsel or professional advice in business, financial, legal, or technical matters.